
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 오토트레이딩
- pandas
- MPRO
- 강화학습으로주식하기
- DL
- 도커로 깃블로그 만들기
- transformer
- socket.io
- 벨만방정식
- 프레딧
- node.js
- TimeSeries
- YOLO
- express
- 프로바이오틱스
- DLInear
- NLinear
- 불법마약특별단속 #부산지방경찰청
- RL
- 강화학습
- 흥미붙이기
- 제발쉽게좀가르치자
- HY7714
- ML
- LTSF
- DataProcessing
- mlflow
- 엠프로
- de
- AI
- Today
- Total
상황파악
파이썬과 케라스로 배우는 강화학습 #1. 개요 본문
참고자료 - https://wikibook.co.kr/reinforcement-learning/
파이썬과 케라스로 배우는 강화학습: 내 손으로 직접 구현하는 게임 인공지능
“강화학습을 쉽게 이해하고 코드로 구현하기” 강화학습의 기초부터 최근 알고리즘까지 친절하게 설명한다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지
wikibook.co.kr
--> 설명이 친절하게 잘 되어 있다고 느낌
--> 앞으로 이 책을 통해 공부한 내용들을 정리할 예정임
--> 쓰다보니 책의 표현이 너무 찰떡이라 적절한 대체제가 떠오르지 않아 책에 있는 표현과 예시를 그대로 옮기는 경우가 많이 생겼는데 행여나 문제가 된다면 수정할 예정
강화학습?
이전에 배우지 않았지만 직접 시도하면서 행동과 그 결과로 나타나는 좋은 보상 사이의 상관관계를 학습하는 것
쉽게말해, 하나씩 시도해보면서 좋은 보상이 나타나는 방법을 익히는 것
머신러닝과 강화학습
💡 머신러닝
기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습해서 실행할 수 있도록 하는 알고리즘을 개발하는 연구분야, 아서 사무엘 (1959)
주어진 데이터를 기반으로 이것저것 해보면서 얻게되는 보상을 통해 (간접적으로 정답의 역할을 함, 지도/비지도 학습과의 차이) 보상을 얻게 하는 행동을 점점 많이 하도록 학습함
에이전트 (Agent)
강화학습을 통해 스스로 학습하는 대상.
환경 (동작할 공간) 에 대한 사전지식이 없는 상태에서 학습을 함.

강화학습은 사람처럼 환경과 상호작용을 하면서 스스로 학습하는 방식이다.
예) 오후 2시쯤에 A라는 장소까지 가야 함
이동방법 : [도보, 버스, 지하철, 택시]
월요일 : 걸어간다 -> 지각 (거리가 멀어서 다리도 아프고 땀이 남. 잔소리를 들어서 기분이 안좋아짐)
화요일 : 버스를 탄다 -> 지각 (걷는것보다 시원하고, 편했지만 차가 많이 막혀 늦음. 잔소리 들음)
수요일 : 지하철을 탄다 -> 정각에 도착 (지하철에 사람이 많아서 덥고 힘들었음. 하지만 늦지는 않음)
목요일 : 택시를 탐 -> 일찍 도착 (하지만 이전 방법들에 비해 비용이 많이 발생함. 하지만 편했음)
=> 금요일 : 조금 일찍 출발해서 여유롭게 버스를 탐 (편하고 잔소리도 듣지 않음)
여러 조건이 고정되어 있지 않았기 때문에 좋은 예시로 보기는 어렵지만, 큰 맥락으로 보면 강화학습의 매커니즘과 유사하다.
정답은 없지만 가장 효과적이라 판단되는 방법을 여러 시행착오를 통해 알아낸 것이다.
강화학습 문제
강화학습은 순차적으로 결정을 내려야 하는 문제에 적용된다.
예를 들면 A 장소까지 도보로 이동하면서 마주하는 길목 중, 여기서는 어떤 골목으로 가야 하는지 결정하는 것 처럼.
물론 순차적 행동 결정문제를 강화학습으로만 풀 수 있는 것은 아니고, DP나 진화 알고리즘 등 다양한 방법으로도 해결할 수 있다.
하지만 각기 방법들은 한계를 가지고 있으며 강화학습이 그 한계를 극복할 수 있다.
우리가 풀어내고 싶은 문제를 컴퓨터에 맏기기 위해서는 컴퓨터가 이해할 수 있는 형태로, 코드로 풀어낼 수 있는 형태로 변환해야 한다.
즉, 문제를 수학적으로 표현해야 한다는 것이다. 풀고자 하는 문제를 수학적으로 정의할 때 사용하는 방법이 MDP (Markov Decision Process) 이다.
MDP
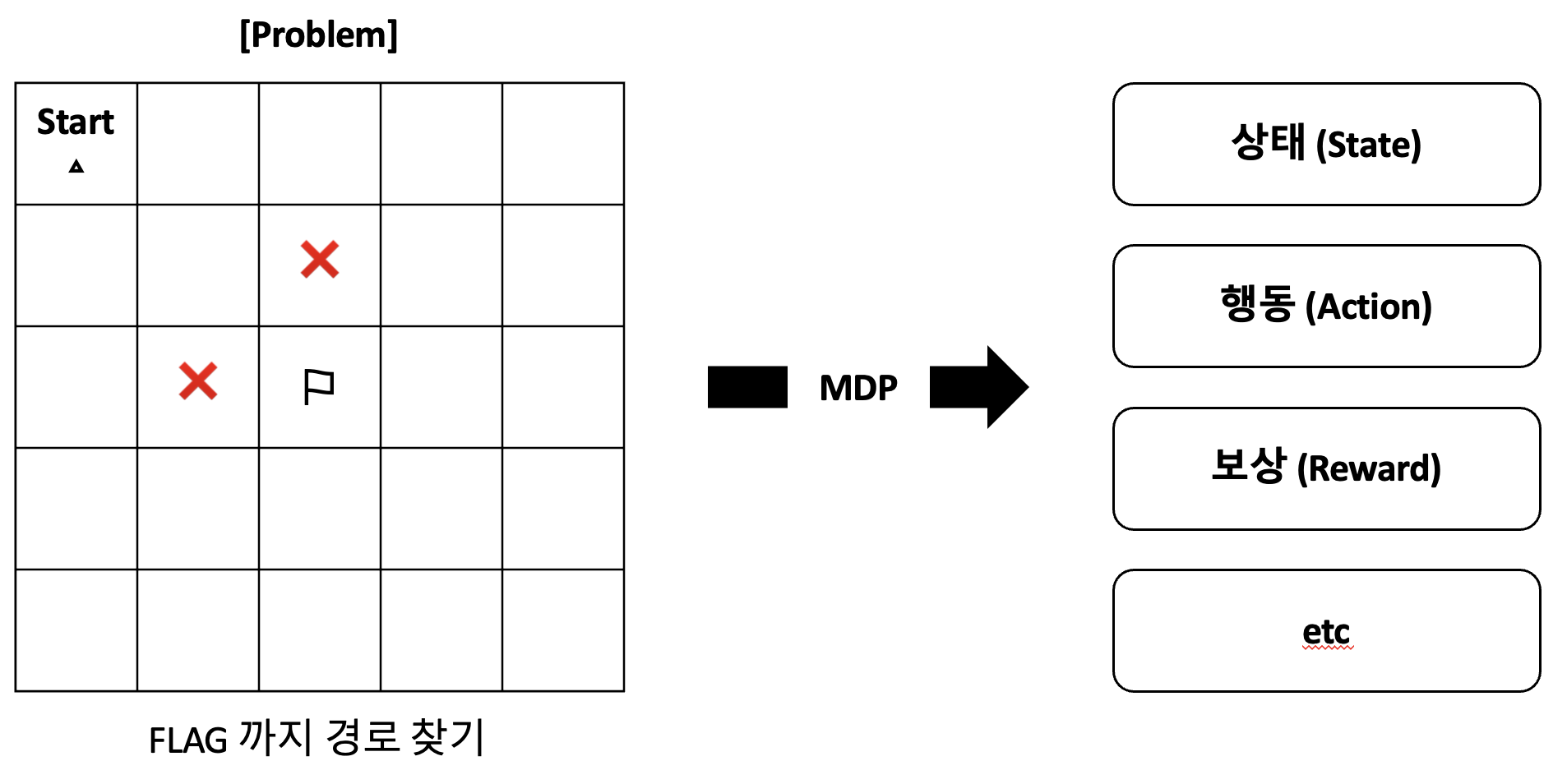
사람은 왼쪽 그림만 봤을때 대충 어떤걸 하려는지 한눈에 알 수 있다. 하지만 컴퓨터는 본다라는 과정도 없기 때문에 친절히 세팅을 해줘야 한다.
MDP란 순차적 행동 결정 문제를 수학적으로 정의해서, 에이전트가 문제에 접근할 수 있게 하는 과정이다. 수학적으로 정의된 문제들은 대표적으로 아래 요소들로 구성된다. 다른요소들이 있지만 큰 개념들만 설명한다.
[MDP] 상태 (State)
에이전트의 상태.
에이전트가 어디에 있는지, 어떤 상태에 있는지 같은 정적인 요소 뿐만 아니라,
어디로 움직이고 있는지, 속도는 어떠한지 등 동적인 요소 또한 상태로 표현할 수 있다.
에이전트가 상태를 통해 어떤 상태에 놓여지는 것이 최대의 보상을 얻을 수 있는지 결정 (해당 상태에 놓여지기 위해 행동을 함) 하기 때문에 충분한 정보를 제공하는 것 (상태의 정의) 이 중요하다.
책에서는 탁구를 예시로 들고 있는데, 에이전트가 탁구공 위치만 알고 속도와 가속도를 모른다면 사실상 탁구를 제대로 칠 수가 없다는 것이다.
[MDP] 행동 (Action)
에이전트가 수행할 동작. (예-2D Matrix에서 가능한 행동은 상/하/좌/우 4중 택1)
에이전트가 어떠한 상태에서 취할 수 있는 행동으로, 처음에는 어떤 행동이 좋은건지 정보가 전혀 없다. 그래서 무작위 행동을 수행한다.
행동을 수행하고 상황이 변화면 그에따른 보상을 받으면서 어떤 상황에서 어떤 행동을 하는 것이 좋은 보상을 받는 방법인지를 학습하게 된다.
[MDP] 보상 (Reward)
에이전트가 놓인 상황에 따른 결과값. (예-목적지 도달 : 1, 반대 방향 이동 : -1, 정방향 이동 : 0)
에이전트가 학습할 수 있는 유일한 정보이자 에이전트에 속하지 않는 환경의 일부로, 다른 머신러닝 기법과 다르게 만들어주는 핵심적인 요소.
강화학습의 목표는 시간에 따라 얻는 보상들의 합을 최대로 하는 정책을 찾는것.
정책 (policy)
모든 상태에 대해 에이전트가 수행해야 할 내용을 정해둔 것. MDP 구해야 할 정답
사실 가장 이해가 어려웠던 부분이 정책이다.
일반적인 ML의 경우 input을 개별 weight와 activation function에 따라 연산을 수행하여 결과가 나온다.
하지만 정책이라는 것은 '상태'를 입력으로 받고, 그에따른 Best Case를 선택한다는 내용이
기존 ML의 inference 과정으로 설명하기에 이질감이 들었기 때문이다.
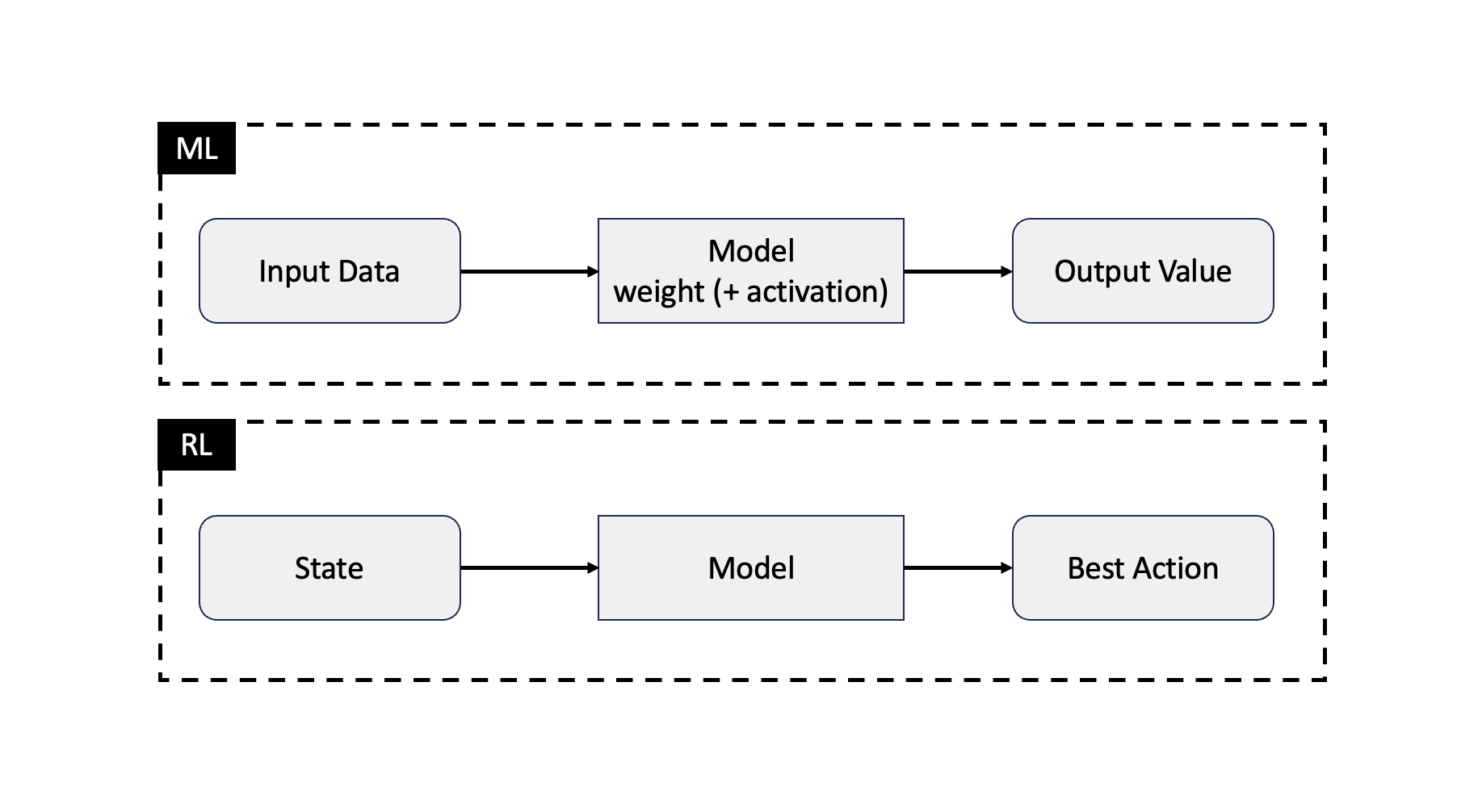
여기서 state는 우리가 일반적으로 주는 feature 라고 이해할 수 있었다.
기온예측이라고 가정하면 강수량, 풍향, 계절, 미세먼지 여부 등
그렇다면 Best Action이라는게 뭘까 싶었다. softmax 같은건가 싶었다.
책을 읽다보니 대략적으로 짐작하게 된 내용을 정리하자면.
에이전트가 할 수 있는 행동은 이미 정해져있다. (일종의 Model의 Output shape/channel)
그러면 기존에 학습했던 내용 (혹은 최초실행으로써 랜덤실행) 을 기반으로 각 행동을 했을때 예상되는 보상을 계산한다.
-> 내가 지금 의자위에 서있는데 (state) 앞으로 다리를 뻗으면 (Action) 아마도 넘어질것 (Reward) 같다.
각 행동별로 계산한 예상 기대값 중, 가장 큰 보상을 받을 수 있는 행동을 Best Action으로 선정하고 실행한다.
-> 의자위에서는 그냥 다시 앉는게 가장 이득인거 같다 (왜냐면 다른게 다 손해라서 상대적 Max 값)
이런 상황들이 순차적으로 이어지면서 (의자에 올라갔다가 앉았다가 돌아다녔다가 밖으로 나갔다가 등등) 각 상황에 어떤 행동을 하는게 이득인지를 결정한 것. (이럴때는 이렇게 하는게 제일 좋더라, (1,1) 에서 (1,2) 로 가는게 제일 좋더라 등)
당연히 train 을 얼마하지 않은 경우엔 각 상황에 따른 best action 이라고 판단한 것이 실제로 Best 가 아닐확률이 높다.
하지만 에이전트가 행동을 통해 상황과 계속 상호작용을 하고 학습을 하면서 (Optimizing, 보상의 합을 최대로 받는 방법을 고민함) 제일 좋은 정책 (Opimal policy, 모든 상황에 대해 최대 보상을 받는 가이드라인) 를 얻어가는 과정을 수행하는 것이다.
'AI > 강화학습' 카테고리의 다른 글
| [Q-learning] 데이터로 설명하기 (0) | 2024.01.09 |
|---|---|
| Toy Proj. 강화학습으로 주식하기 (1) | 2023.12.28 |
| 제발 좀 쉽게 가르치자 - 강화학습 1편 (0) | 2023.10.09 |
| 파이썬과 케라스로 배우는 강화학습 #2. MDP와 벨만 방정식 (0) | 2023.08.26 |



