
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 흥미붙이기
- pandas
- 벨만방정식
- 엠프로
- AI
- DataProcessing
- RL
- 오토트레이딩
- 도커로 깃블로그 만들기
- DLInear
- transformer
- 제발쉽게좀가르치자
- MPRO
- 프로바이오틱스
- 강화학습
- 프레딧
- ML
- node.js
- HY7714
- express
- LTSF
- YOLO
- DL
- 불법마약특별단속 #부산지방경찰청
- NLinear
- de
- 강화학습으로주식하기
- TimeSeries
- socket.io
- mlflow
- Today
- Total
상황파악
Python pandas 간단 설명 본문
이번 프로젝트를 진행하면서 데이터 처리에 관하여 공부하였습니다.
대용량 csv 파일을 읽어들이는 작업이 필요했는데 이때 사용된 방법이 python의 pandas입니다.
pandas란?
'데이터 조작 및 분석을 위해 사용하는 python 라이브러리'
정말 군더더기 없이 간결하게 잘 정의되어있습니다.
한마디로 데이터를 원하는 형식대로 가지고 놀겠다는 뜻입니다.
처음 pandas를 접했을 때 패닉이 왔었습니다.
dataframe, series... 이게 도대체 무슨 말이지...
그것보다도 도대체 이걸 왜 쓰는건지 이해가 안되었습니다.
Dataframe이란 뭐하는 건가요??
dataframe은 테이블 형태로 읽어들인 데이터 타입입니다.
다른 설명글을 보면 dataframe을 선언하는 것 부터 시작하지만 개인적으로 잘 이해가 되지 않았습니다.
왜냐면 전 당장 이 csv 파일을 처리해야 했기 때문입니다.
바로 csv 파일에 적용하는 법으로 적겠습니다.
사용법
텍스트 파일(txt, csv 등)을 제가 원하는 형태로 가공할 때 굉장한 역할을 해주는 녀석입니다.
저는 csv 밖에 써보지 않았기 때문에 csv를 기준으로 설명하겠습니다.
사용에 앞서 먼저 다운로드를 받습니다.
cmd를 열어 다음 명령어를 입력하여 pandas를 다운로드 받습니다.
pip install pandas
다운로드를 마쳤으면 사용을 해보겠습니다.
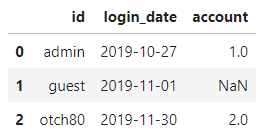
위와 같은 csv파일이 존재한다고 가정했을 때, '파일을 실행시키지 않고 id를 다 없애고싶다.'
이러한 과정을 python코드로 동작하는데, 이때 pandas를 사용하여 작업을 수월하게 해줍니다.
# pandas를 쓸건데 pd로 부릅니다
import pandas as pd
# pandas의 read_csv 함수를 이용하여 'test.csv'파일을 불러들여서 f라는 변수에 저장합니다
# 이때 f의 type은 DataFrame입니다.
f = pd.read_csv('test.csv')
# f 변수에 들어있는 데이터프레임에서 column값이 'id'인 열을 제거합니다. 이때 id는 열입니다.
f.drop(['id'],axiw=1)
이때 NaN은 결측치. 즉 비어있는 null값입니다.
물론 엑셀을 직접 실행시켜 열 제거를 해도 상관없습니다.
하지만 대용량의 csv라면 파일 실행도 정상적으로 이루어 지지 않고, 작업시간도 굉장히 오래 걸리게 됩니다.
DataFrame? Series?
정확한 사실 인지는 모르겠습니다만 제가 프로젝트를 진행하면서 이해한 내용으로 설명 드리겠습니다.
파이썬에는 정말 다양한 데이터의 형식이 존재합니다.
list, dict, tuple, serires, dataframe, timestamp, datetime, int64, 등등...
파이썬에서 공식적으로 정의된 데이터 형식인지는 모르겠으나 에러화면에서 가장 많이 보았던 녀석들입니다.
위에서 설명한 것 처럼 pandas의 read_csv를 통해 csv파일을 읽어 들이게 되면 dataframe의 형식으로 읽어 들입니다.
이 중 f['id']와 같이 특정 열 부분만 가져온 경우 series가 됩니다.
쉽게 말해 series가 모여 dataframe이 됩니다.
각 원소들이 모여 list가 되는 것 처럼 말이죠
그렇다면 series는 뭐가 모여서 만들어 진 것인가?
행이 모여서 만들어 집니다.
행은 뭐... 각 셀들이 모여서 만들어지겠죠?
이렇게 작은 원소들이 모여모여서 하나의 dataframe을 이룹니다.
엑셀 파일을 만들기 귀찮은데 코드로 데이터 프레임을 만들 수 없나요?
a = pd.DataFrame({'a':[1],'b'[2]})위 코드처럼 데이터 프레임을 생성하는 것도 가능합니다.
그런데 귀찮습니다.
개인적으로 엑셀 작업이 더 편해서 csv파일을 만들어서 사용합니다.
DataFrame을 생성하는 방법에는 다양한 방법이 존재합니다.
serires to Dataframe, dictionary to Dataframe, list to Dataframe등 다양한 데이터 타입에서 DataFrame으로 변환하는 작업도 많이 사용됩니다.
이는 상황에 따라 다르게 적용하며 필요에 따라 맞게 사용하시면 됩니다.
추가로 pandas를 찾아보면 자연스럽게 따라오는것이 있는데 바로, numpy 입니다.
NUmpy는 또 뭐에요?
numpy는 pandas의 하위 버전이라고 이해하시면 될 것 같습니다.
물론 다른점도 존재합니다.
하지만 pandas가 작업속도나 편의성 면에서 굉장히 뛰어나다고 생각이 듭니다.
numpy만의 기능도 있지만 pandas 내에서 거의 다 처리가 되기 때문에 필요하지 않은 이상 pandas만 봐도 무방할 듯 합니다.
추가로 open을 사용하여 파일을 읽는 방법도 있는데 이는 굉장히 비효율 적이라 생각이 듭니다.
이 역시 필요에 따라서 사용할 수 있겠지만 pandas로 할 수 있는 작업이기 때문에 굳이 text파일이라면 pandas를 사용하는 것을 추천 드립니다.
이상 pandas 간단 설명 마무리 하겠습니다.
'파이썬' 카테고리의 다른 글
| 파이썬 - 람다 (lambda) (0) | 2021.01.07 |
|---|---|
| 파이썬 - 제너레이터 (Generator) (0) | 2021.01.04 |